
August 8, 2025
Have LLMs hit a wall?
GPT-5 landed with a shrug. Why wasn’t it the breakthrough OpenAI promised?
Why GPT-5 Feels Underwhelming
AI researcher Rich Sutton once wrote: "The bitter lesson". The tl;dr (it's short - go read it) is a brutal reminder that in the long run, raw computation and general methods beat clever, human-designed tricks.
For decades, researchers tried to beat humans at chess with elegant heuristics. Then someone came along with a bigger computer and a brute-force search, and wiped them out. Same thing with Go, with speech recognition, and with computer vision.
I learned this lesson the hard way. For my undergrad dissertation, I tried to find crops in satellite images using edge detection, pattern recognition, contrast normalisation: all clever methods I was proud of. And what worked best? A humble convolution filter backed by the universities compute and storage.
I think I'm seeing the same thing happen with Large Language models. Hear me out.
We threw massive compute and data at a problem and created something revolutionary. Transformers were invented, people started tinkering with them, but I don't think anyone really understood the groundbreaking change that was going to happen when OpenAI released their GPT models to the public. For free. I call this the 'research era'. Giddy researchers creating cool things in the backrooms of large organisations, but the world doesn't fully know about them, and, more importantly, the research hasn't been tainted by capitalistic motivations. We saw a preview of this shift when Blake Lemoine was fired from Google after claiming their LLM (then called Bard) was sentient.
Anyway, I digress. Research came out, we didn't have the compute. Nvidia provided the compute, now we have Gemini, ChatGPT, Claude etc etc. Sooo... Why was GPT-5 so underwhelming? It's because I believe we're past the 'computation era', and we've reached the heuristic era of LLMs.
The Heuristic Era?
In a gold rush, it's the folks that sell the spades that make the money. We've all heard this before. You get a bigger spade - you can dig for more gold. Same applies here - the more compute and data you can throw at training these models, the better the model becomes. In the early days, we had lots of compute and data still to use.
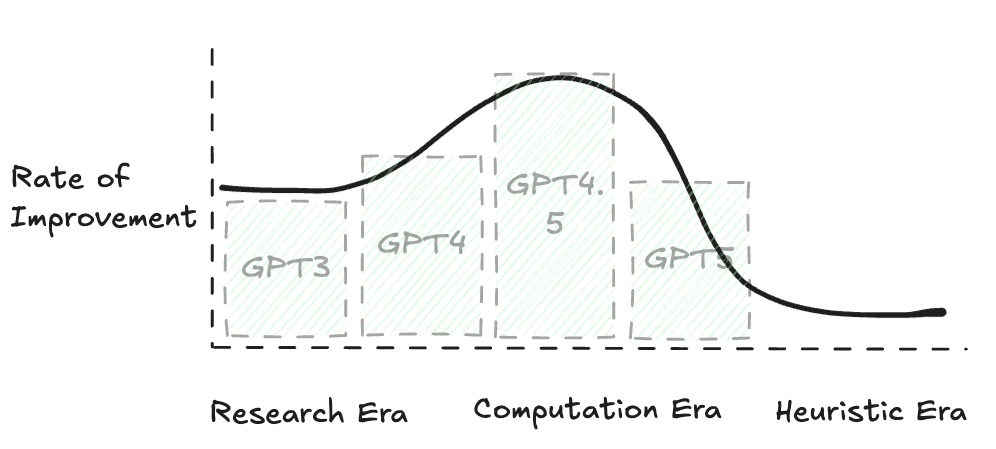
This is what I call the computation era. Hyperscalers with huge GPU clusters (thanks, Nvidia) raced to train ever-larger models. OpenAI, Google, Anthropic… each leap forward came from more chips, more data, and bigger training runs. But something’s changed. The data well is running dry. Legal pushback is shrinking what can be scraped. The internet is, for the most part, already in the training set. Meanwhile, Nvidia’s next-gen Blackwell GPUs are struggling to land in quantity.
We’ve hit the point where bigger spades aren’t easy to come by.
The playing field is evening up, and the competitive advantages we're seeing are no longer based on what chips you have access to, or what data you have access to, but moreso what kind of heuristics we can throw at our models to extract more intelligence. Chain-of-Thought, multi-agent systems, Retrieval-Augmented Generation (RAG). These feel like a return to the very "heuristics" Sutton's lesson warned against. To be clear, the practical utility of these new heuristic-driven systems is enormous and represents real progress. But it's a different kind of progress. When you can’t scale the engine, you start bolting on turbos. Improvements can be made, but there's only so much energy we can extract from internal combustion.
So what's next for these big providers?
Assuming a revolutionary new supply of compute or data isn't on the immediate horizon, where do the big AI labs go next? If we can't build bigger, we have to build smarter. Three paths seem to be emerging:
- Synthetic Data: Can AI teach itself? Sam Altman and others suggest this is a path toward AGI, mirroring how AlphaGo trained itself through self-play. This works to a degree, but it also carries the significant risk of "model collapse," where an AI learning from its own output enters a degenerative spiral of weirdness.
- True Multimodality: Text is just one slice of information. There is a universe of untapped data in voice, video, and images that can teach concepts text alone cannot—intuitive physics, social cues, cause and effect. Integrating these modalities could provide a new, rich source of learning to drive progress.
- A New Architecture: Is it time for a true successor to the Transformer? The 'Human Ingenuity' path is a bet that researchers can discover a fundamentally new architecture that resets the scaling laws and kicks off a new era of growth. But The Bitter Lesson looms large: is this pursuit just another "clever trick" destined to fail, or the one that breaks the pattern?
So what now?
GPT-5 is here. It has impressive reasoning tricks, multimodality, chain-of-thought. All the headline features. But to me, the core model, the raw transformer under the hood, doesn’t feel radically more intelligent. The improvements are mostly in the scaffolding around the model, not in the skyscraper itself.
We’re in the heuristic era: smarter wrappers, clever workflows, better integrations. That’s progress, but it’s not the same kind of leap we got from the raw scaling of compute and data. Maybe the new Bitter Lesson is this: even our entire species’ accumulated knowledge is just the starting point. The long-term path for AI isn’t just to learn from us. It’s to learn how to learn on its own.
“We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.” — Rich Sutton
Footnote
I didn't talk about inference, just training, but that's because I believe our inference capability is tied to the compute required to create these models.